DBT Custom Materializations
Background:
Background:
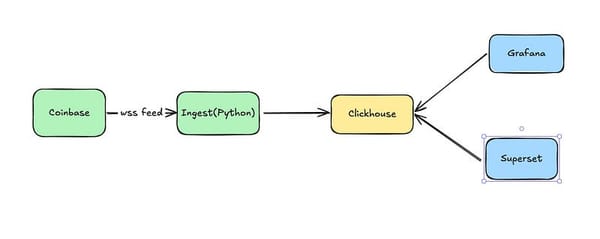
In a prior post, I talked about building out a simple data platform with support for streaming data. I left off with a basic, working platform, which you can find the code for here. The downside was that it had quite a few scaling issues. One of the glaring scaling issues is that all of the SQL we have written to this point is completely ad-hoc. There is no good way to figure out what is going on other than poking around the database and looking at table definitions. It works in a toy example and might even survive the first few months of a real world implementation but will quickly turn into a nightmare after that. Enter DBT. With it we can apply software engineering practices to our transformation code.
In this article, we’ll begin refining our platform to be easier to maintain. DBT gives us the capability to define our models and manage them in a way that is consistent with good software engineering practices. Before we can use DBT more broadly in this project though, there is a small technical hurdle — The ClickHouse adapter does not support materialized views, which we saw in the last post are critical if we want a performant streaming data platform. In this article I’ll walk through one approach to bridging that gap.
Introduction:
DBT, as most data engineering tools, is focused on the batch space. There is good reason for that — most of the time batch is all you need, and it is simpler. But in my previous post I called out some places where you really do need streaming — and when you need it, well, there is no substitute.
DBT supports incremental models — but this really isn’t what we need. Incremental models allow us to build the content of our models, you guessed it, incrementally from a source. It is a great feature but is intended to reduce the latency of building large, expensive models, not as a substitute for handling streaming data.
As we saw before, ClickHouse has support for materialized views that support streaming… but their DBT adapter doesn’t support them. Fortunately, DBT provides a workaround that lets us get to the solution we want and take full advantage of DBT and ClickHouse together. Enter custom materializations.
Why create a custom materialization? Why not just a model? A DBT model makes the transformation we are applying the first-class citizen. The definition of how the result of that transformation is materialized is moved to configuration. This creates a clear separation between what and how. The difference becomes evident in this example:
{{ config(
materialized='table',
engine='MergeTree()',
order_by='trade_time'
) }}
with source as (
select * from {{ source('stg_coinbase__sources', 'coinbase_ticker') }}
)
select
sequence as sequence_id,
trade_id,
price,
last_size,
time as trade_time,
product_id,
side,
open_24h,
volume_24h,
low_24h,
high_24h,
volume_30d,
best_bid,
best_ask,
best_bid_size,
best_ask_size
from sourceIn this model we define how to store the data — as a table using the merge tree engine — in configuration. We also explicitly define the transformation that provides our data in the select statement. This mechanism puts the focus on the transform.
That is NOT what defining a ClickHouse materialized view looks like. The difference is subtle, but important. Here’s the SQL I used in the last post
CREATE MATERIALIZED VIEW IF NOT EXISTS coinbase_demo.trades_per_minute_mv
TO coinbase_demo.trades_per_minute
AS
SELECT
tumbleStart(time, toIntervalMinute(1)) as minute,
countIf(last_size > 0) as num_trades
FROM coinbase_demo.coinbase_ticker
GROUP BY minute;There is a select statement in there, but this is DDL. We’re defining the table, including the instructions for where to get the data. The transformation, in the SELECT statement, and the materialization, the CREATE statement are jumbled together. While it is doing the exact same thing it is not clearly separated like the DBT model. More concretely for our purposes — since the transformation isn’t defined on its own DBT isn’t going to be able to handle it.
A DBT custom materialization allows us to define a macro which generates the above DDL. That gives us a path to using the same mechanism for materialized views that we use for tables or incremental views. If you want the full code you can find it on my GitHub.
Clickhouse Materialized View Details
Before we talk about the custom materialization itself let’s understand ClickHouse Materialized Views a bit better. A Materialized View logically consists of two parts — the table where the data is stored and the view definition that populates the table. You have the option to either explicitly define the table and then define a view to populate that table, or to just define the view, and ClickHouse will implicitly create the table for you. I’ve chosen to explicitly create the table for an important reason — ClickHouse Materialized Views must select from tables. I want to be able to define a chain of models updating from streaming data, so I need to have the table available.
If you look again at the materialized view definition above, you’ll notice the 'TO' keyword. That tells us we are defining a materialized view which populates an externally defined table. This definition would create a similar view with the table implicitly defined:
CREATE MATERIALIZED VIEW IF NOT EXISTS coinbase_demo.trades_per_minute_mv
ENGINE=SummingMergeTree()
ORDER BY minute
SELECT
tumbleStart(time, toIntervalMinute(1)) as minute,
countIf(last_size > 0) as num_trades
FROM coinbase_demo.coinbase_ticker
GROUP BY minute;In the custom materialization I only support externally defined tables so far, but it is straightforward to add support for an implicit table.
Model Definition
We’ll start to understand the custom materialization by looking at an example of the model that uses it. I’ll pick a slightly simpler one than you saw above:
{{ config(
materialized='clickhouse_materialized_view',
materialization_schema='coinbase_demo',
materialization_identifier='int_trades_per_minute',
order_by='minute'
) }}
SELECT
tumbleStart(trade_time, toIntervalMinute(1)) as minute,
countIf(last_size > 0) as num_trades
FROM {{ ref('stg_coinbase__trades') }}
GROUP BY minuteThe config section defines the materialization for our model.
materialized='clickhouse_materialized_view',This is used by DBT to select the materialization it will use for this model. Since DBT supports custom materialization there is a possibility for conflict. DBT defines a clear precedence for selecting which materialization it will use:
- global project — default
- global project — plugin specific
- imported package — default
- imported package — plugin specific
- local project — default
- local project — plugin specific
The next three parameters are defined by our custom materialization:
materialization_schema='coinbase_demo',
materialization_identifier='int_trades_per_minute',
order_by='minute'Finally we have the SQL describing how to populate the view. There is one important line in here:
FROM {{ ref('stg_coinbase__trades') }}By using this ref rather than directly stating the name of the table, we are resilient to change (as long as the model’s name stays the same) and DBT becomes aware of dependencies. This allows it to construct a DAG that gives us both execution order and lineage.
Materialization Definition
The first line of our materialization code tells DBT how to match a model to this materialization
{% materialization clickhouse_materialized_view, adapter='clickhouse' %}You can see that clickhouse_materialized_view matches the ‘materialized’ property in our config.
After that we get the required configuration properties
{%- set materialization_schema = config.require('materialization_schema') -%}
{%- set materialization_identifier = config.require('materialization_identifier') -%}
{%- set order_by = config.require('order_by') -%}If you want to take on the exercise of generalizing this code, you’ll want to make the order_by property not required.
Next, I create a relation object from config properties:
{%- set materialization_table = api.Relation.create(
database=materialization_schema,
schema=materialization_schema,
identifier=materialization_identifier,
type='table'
) -%}I do this to point to the table we are populating in the ‘TO’ clause. I could have used string concatenation as well, but this approach is more robust. I don’t have to worry about getting it right if we are in the default schema, for example.
The next step conforms us to DBT config expectations. It allows authors of models to define hooks that get run pre or post creation
{{ run_hooks(pre_hooks) }}To understand the need for the next section, remember this code:
with source as (
select * from {{ source('stg_coinbase__sources', 'coinbase_ticker') }}
)We’re using a macro here to point our model at a source table. Since we expect to be able to use macros in our models, we’d best support that in our materialization by rendering:
{%- set compiled_sql = render(sql) -%}Finally, we get to the meat of it, where we define the DDL. If you look back at the SQL definition of a materialized view, the mapping here is pretty straightforward:
{%- set ddl -%}
CREATE MATERIALIZED VIEW IF NOT EXISTS {{ target_relation }}
TO {{ materialization_table }}
AS {{ compiled_sql }}
{%- endset -%}All that remains now is to call the DDL statement we’ve created, run the post hooks, and return the relation we’ve created:
{% call statement('main') -%}
{{ ddl }}
{%- endcall %}
{{ run_hooks(post_hooks) }}
{{ return({'relations': [target_relation]}) }}With that, we’ve got a working materialized view again but with much better maintainability. Since we were careful to make sure that macros work and to use source and ref appropriately, we can take advantage of DBTs documentation and lineage features as well.
Conclusion
DBT provides us with the capability to use good software engineering practices for managing our transformation code. It does not cover every capability of all storage engines out of the box, but it does provide us with the ability to extend its capabilities through macros and custom materializations. I’ve shown one approach for using that capability to build support for ClickHouse materialized views, giving us the ability to build an efficient pipeline for streaming data in ClickHouse, with transforms managed by DBT. In my next piece I’ll use this capability to make further improvements to our simple streaming data platform.
I’d love to hear how you have made use of DBTs custom materializations in the comments.
Like this article? Clap 👏 or share it on LinkedIn and tag me! It really helps me out. Thank You!